這一個月來心情起伏很大........我早就知道機器學習和深度學習的課程難度,理解很簡單,做好不容易,成為專家更是要下苦功....
昨天忙了一整天,晚上跑數字辨識的神經網路,吃GPU結果,發現顯卡不夠力,害我守在電腦前一直到3點多才上床,今天又跑了一整天,直到剛才,整整花了24個小時.....
我真想對跟了我5年的筆電說Good job,早上還同時多工tuning另一個深度學習的預測......
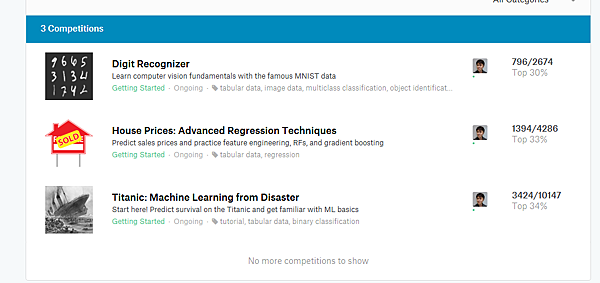
這是我參加三個練習賽的成績,數字辨識前30%,波士頓房價預測前33%,鐵達尼生存預測前34%,3選2,前30%~40%名次可得35分
兩個就是70分,認證要求是60分,哈....分數不高,但我很滿足了,另外兩個正式賽靠尾鰭的照片辨識出座頭鯨及加分題貓狗圖片辨識,難度太高,只好慢慢的研究了.....
我就用波士頓房價預測為例來說明好了......
1. 順序一定是將測試資料集和訓練資料集讀進dataFrame,然後做資料的清理和整理。
2. 接下來找出對房價的相關因子變數
3. 接下來選用迴歸模型訓練你的Model(訓練資料集)
4. 最後用測試資料集跑預測結果
我第一次跑完結果的成績約前68%,幾乎在後1/3,接下來我把所有迴歸模型(和多種迴歸混合預測)都試過一次找出最棒的預測結果,但每次只有前進50~100多名....
遇到瓶頸之後在回去檢視是否有遺漏的參數條件,剛開始餵了整理方便會直接選用有數值的參數來跑模型,但想要再提升就必須連描述分類的資料也要納入分析
我剛開始還不不太會整理資料,因此就只能用土法煉鋼的方式,一個一個參數跑結果,結果試了20多次,但我的參數展開最後留下的有70個.......這樣終於達到一個不錯的分數,進步了300多名....
但又遇到瓶頸了,成績一直卡在前60%左右,最後想到一件事,訓練資料有1600筆,測試資料也有1600筆,如果我把最佳的測試資料的預測結果也加入訓練資料那會如何?
結果我的訓練資料來到3200筆,終於又前進了好幾百名,來到前54%但又卡關了........
只好上網找援助,觀看別人如何解決類似的問題......終於發現,原來高手一開始早就將兩個資料集合併了,併開始分析null值和空值,補資料,然後針對每個條件做分析和判斷是否是影響因子
跑出正負相關的排序後,接下來跑出MSE值(預測和實際的距離值),然後給予權重的修正
原來就是差了幾個負相關的因子和權重修正,我補上之後,終於預測值來到了前33%.......知道了做法之後,後續的就比較知道如何處理........
但是.......前30%又已經是瓶頸了,接下來每差個0.00001的預測就會差個好幾名......真崇拜那些前1%~5%的頂尖高手,到底如何達到99.999%或100%的預測準確度..?
不過上課時老師有提到過擬合的問題,就是如果訓練過度符合預測結果,這樣一但測試資料或些微的變異,可能就會讓模型準確度下降.....
不管如何,總算在明天作業繳交前完成了上傳,終於可以比較安心的過年了,我目前只是剛出新手村,要到職場上可以順利的運用還有很長的路要走,
但今天我已經想到了許多機器學習和深度學習可以運用的商機了.........很開心又跨入了一個新領域,持續的學習和成長


 留言列表
留言列表
 {{ article.title }}
{{ article.title }}